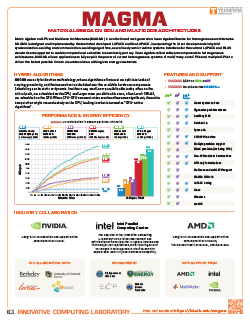
Matrix Algebra on GPU and Multi-core Architectures (MAGMA) is a collection of next-generation linear algebra libraries for heterogeneous computing. The MAGMA package supports interfaces for current linear algebra packages and standards (e.g., LAPACK and BLAS) to enable computational scientists to easily port any linear algebra–reliant software components to heterogeneous computing systems. MAGMA enables applications to fully exploit the power of current hybrid systems of many-core CPUs and multi-GPUs/coprocessors to deliver the fastest possible time to accurate solutions within given energy constraints.
MAGMA features LAPACK-compliant routines for multi-core CPUs enhanced with NVIDIA or AMD GPUs. MAGMA 2.5.4 now includes more than 400 routines that cover one-sided dense matrix factorizations and solvers, two-sided factorizations, and eigen/singular-value problem solvers, as well as a subset of highly optimized BLAS for GPUs. A MagmaDNN package has been added and further enhanced to provide high-performance data analytics, including functionalities for machine learning applications that use MAGMA as their computational back end. The MAGMA Sparse and MAGMA Batched packages have been included since MAGMA 1.6.
Please use any of these publications to reference MAGMA.
A neural network library in c++ aimed at providing a simple, modularized framework for deep learning that is accelerated for heterogeneous architectures. MagmaDNN's releases are located at https://bitbucket.org/icl/magmadnn (and here), while active development occurs at https://github.com/MagmaDNN/magmadnn/tree/dev. If you're looking to contribute or submit a pull-requests/issues, then please do so on the github development repository.

In version 1.0 MagmaDNN offers a strong tensor core with standard machine learning and DNN functionalities built around it. For nightly development builds use the github repository linked above.
MagmaDNN is optimized towards heterogeneous architectures (multi-core CPU and GPU), so it is advised to use with a modern NVIDIA GPU. However, MagmaDNN does support a CPU only install. This is mainly meant for testing and is not nearly as optimized as the GPU version.
The documentation can be found on the docs site. For the most recent version of the documentation see the build & install tutorial on how to build the docs from source. The todo page contains information on the future of the package and the troubleshooting page walks through common issues and there solution.
There are several tutorials in docs/tutorials. These give an introduction into installing and using the library.
For examples of what MagmaDNN code looks like see the examples/ folder. If MagmaDNN is downloaded and installed, then the examples can be made and run with make examples.
All development takes place on the github site.






author: Daniel Nichols
co-authors: Florent Lopez, Sedrick Keh, Rocco Febbo
MAGMA MIC 1.4.0 is now available. This release provides implementations for MAGMA's one-sided (LU, QR, and Cholesky) and two-sided (Hessenberg, bi- and tridiagonal reductions) dense matrix factorizations, as well as linear and eigenproblem solver for Intel Xeon Phi Coprocessors. More information on the approach is given in this presentation.
clMAGMA is an OpenCL port of MAGMA. It supports AMD GPUs. The clMAGMA library dependancies, in particular optimized GPU OpenCL BLAS and CPU optimized BLAS and LAPACK for AMD hardware, can be found in the AMD clMath Libraries (formerly APPML).
Included in the clMAGMA 1.3 release are routines for the following algorithms:
| “PAQR: Pivoting Avoiding QR factorization,” 2023 IEEE International Parallel and Distributed Processing Symposium (IPDPS), St. Petersburg, FL, USA, IEEE, 2023. |
|
“A Python Library for Matrix Algebra on GPU and Multicore Architectures,”
2022 IEEE 19th International Conference on Mobile Ad Hoc and Smart Systems (MASS), Denver, CO, IEEE, December 2022.
|
|
“Extending MAGMA Portability with OneAPI,”
The International Conference for High Performance Computing, Networking, Storage, and Analysis (SC22), Ninth Workshop on Accelerator Programming Using Directives (WACCPD 2022), Dallas, TX, November 2022.
|
|
Extending MAGMA Portability with OneAPI
, Dallas, TX, The International Conference for High Performance Computing, Networking, Storage, and Analysis (SC22), ACM Student Research Competition, November 2022.
|
|
“Mixed-Precision Algorithm for Finding Selected Eigenvalues and Eigenvectors of Symmetric and Hermitian Matrices,”
ICL Technical Report, no. ICL-UT-21-05, August 2021.
|
|
“Exploiting Block Structures of KKT Matrices for Efficient Solution of Convex Optimization Problems,”
IEEE Access, 2021.
|
|
“Evaluating the Performance of NVIDIA’s A100 Ampere GPU for Sparse and Batched Computations,”
2020 IEEE/ACM Workshop on Performance Modeling, Benchmarking and Simulation of High Performance Computer Systems (PMBS): IEEE, November 2020.
|
|
“High-Order Finite Element Method using Standard and Device-Level Batch GEMM on GPUs,”
2020 IEEE/ACM 11th Workshop on Latest Advances in Scalable Algorithms for Large-Scale Systems (ScalA): IEEE, November 2020.
|
| “MAGMA Templates for Scalable Linear Algebra on Emerging Architectures,” The International Journal of High Performance Computing Applications, vol. 34, issue 6, pp. 645-658, November 2020. |
|
“Matrix Multiplication on Batches of Small Matrices in Half and Half-Complex Precisions,”
Journal of Parallel and Distributed Computing, vol. 145, pp. 188-201, November 2020.
|
|
“Mixed-Precision Iterative Refinement using Tensor Cores on GPUs to Accelerate Solution of Linear Systems,”
Proceedings of the Royal Society A, vol. 476, issue 2243, November 2020.
|
|
“Design, Optimization, and Benchmarking of Dense Linear Algebra Algorithms on AMD GPUs,”
2020 IEEE High Performance Extreme Computing Virtual Conference: IEEE, September 2020.
|
|
“Mixed Precision LU Factorization on GPU Tensor Cores: Reducing Data Movement and Memory Footprint,”
Innovative Computing Laboratory Technical Report, no. ICL-UT-20-13: University of Tennessee, September 2020.
|
|
“Design, Optimization, and Benchmarking of Dense Linear Algebra Algorithms on AMD GPUs,”
Innovative Computing Laboratory Technical Report, no. ICL-UT-20-12: University of Tennessee, August 2020.
|
|
“Ginkgo: A High Performance Numerical Linear Algebra Library,”
Journal of Open Source Software, vol. 5, issue 52, August 2020.
|
|
“Integrating Deep Learning in Domain Sciences at Exascale,”
Innovative Computing Laboratory Technical Report, no. ICL-UT-20-10: University of Tennessee, August 2020.
|
| “Integrating Deep Learning in Domain Sciences at Exascale,” 2020 Smoky Mountains Computational Sciences and Engineering Conference (SMC 2020), August 2020. |
| “Multiprecision Block-Jacobi for Iterative Triangular Solves,” European Conference on Parallel Processing (Euro-Par 2020): Springer, August 2020. |
|
“Translational Process: Mathematical Software Perspective,”
Innovative Computing Laboratory Technical Report, no. ICL-UT-20-11, August 2020.
|
| hipMAGMA v2.0 : Zenodo, July 2020. |
|
“heFFTe: Highly Efficient FFT for Exascale,”
International Conference on Computational Science (ICCS 2020), Amsterdam, Netherlands, June 2020.
|
|
“Sparse Linear Algebra on AMD and NVIDIA GPUs—The Race is On,”
ISC High Performance: Springer, June 2020.
|
|
“Asynchronous SGD for DNN Training on Shared-Memory Parallel Architectures,”
Workshop on Scalable Deep Learning over Parallel And Distributed Infrastructures (ScaDL 2020), May 2020.
|
|
“CEED ECP Milestone Report: Improve Performance and Capabilities of CEED-Enabled ECP Applications on Summit/Sierra,”
ECP Milestone Reports: Zenodo, May 2020.
|
|
“Reducing the Amount of out-of-core Data Access for GPU-Accelerated Randomized SVD,”
Concurrency and Computation: Practice and Experience, April 2020.
|
|
“Asynchronous SGD for DNN Training on Shared-Memory Parallel Architectures,”
Innovative Computing Laboratory Technical Report, no. ICL-UT-20-04: University of Tennessee, Knoxville, March 2020.
|
| hipMAGMA v1.0 : Zenodo, March 2020. |
|
“Load-Balancing Sparse Matrix Vector Product Kernels on GPUs,”
ACM Transactions on Parallel Computing, vol. 7, issue 1, March 2020.
|
|
MATEDOR: MAtrix, TEnsor, and Deep-learning Optimized Routines
, Seattle, WA, 2020 NSF Cyberinfrastructure for Sustained Scientific Innovation (CSSI) Principal Investigator Meeting, February 2020.
|
|
“FFT-ECP API and High-Performance Library Prototype for 2-D and 3-D FFTs on Large-Scale Heterogeneous Systems with GPUs,”
ECP Milestone Report, no. FFT-ECP STML13-27: Innovative Computing Laboratory, University of Tennessee, January 2020.
|
|
“Project-Based Research and Training in High Performance Data Sciences, Data Analytics, and Machine Learning,”
The Journal of Computational Science Education, vol. 11, issue 1, pp. 36-44, January 2020.
|
|
“Impacts of Multi-GPU MPI Collective Communications on Large FFT Computation,”
Workshop on Exascale MPI (ExaMPI) at SC19, Denver, CO, November 2019.
|
|
“Towards Half-Precision Computation for Complex Matrices: A Case Study for Mixed Precision Solvers on GPUs,”
ScalA19: 10th Workshop on Latest Advances in Scalable Algorithms for Large-Scale Systems, Denver, CO, IEEE, November 2019.
|
|
CEED ECP Milestone Report: Performance Tuning of CEED Software and 1st and 2nd Wave Apps
: Zenodo, October 2019.
|
|
“FFT-ECP Implementation Optimizations and Features Phase,”
Innovative Computing Laboratory Technical Report, no. ICL-UT-19-12: University of Tennessee, October 2019.
|
|
“GPUDirect MPI Communications and Optimizations to Accelerate FFTs on Exascale Systems,”
EuroMPI'19 Posters, Zurich, Switzerland, no. icl-ut-19-06: ICL, September 2019.
|
|
“Increasing Accuracy of Iterative Refinement in Limited Floating-Point Arithmetic on Half-Precision Accelerators,”
IEEE High Performance Extreme Computing Conference (HPEC 2019), Best Paper Finalist, Waltham, MA, IEEE, September 2019.
|
|
“Progressive Optimization of Batched LU Factorization on GPUs,”
IEEE High Performance Extreme Computing Conference (HPEC’19), Waltham, MA, IEEE, September 2019.
|
|
“Distributed-Memory Lattice H-Matrix Factorization,”
The International Journal of High Performance Computing Applications, vol. 33, issue 5, pp. 1046–1063, August 2019.
|
|
“MagmaDNN: Accelerated Deep Learning Using MAGMA,”
Practice and Experience in Advanced Research Computing (PEARC ’19), Chicago, IL, ACM, July 2019.
|
|
“OpenDIEL: A Parallel Workflow Engine and DataAnalytics Framework,”
Practice and Experience in Advanced Research Computing (PEARC ’19), Chicago, IL, ACM, July 2019.
|
|
“Hands-on Research and Training in High-Performance Data Sciences, Data Analytics, and Machine Learning for Emerging Environments,”
ISC High Performance, Frankfurt, Germany, Springer International Publishing, June 2019.
|
|
“MagmaDNN: Towards High-Performance Data Analytics and Machine Learning for Data-Driven Scientific Computing,”
ISC High Performance, Frankfurt, Germany, Springer International Publishing, June 2019.
|
|
“Fast Batched Matrix Multiplication for Small Sizes using Half Precision Arithmetic on GPUs,”
33rd IEEE International Parallel and Distributed Processing Symposium (IPDPS), Rio de Janeiro, Brazil, IEEE, May 2019.
|
|
CEED ECP Milestone Report: Public release of CEED 2.0
: Zenodo, April 2019.
|
|
“Design and Implementation for FFT-ECP on Distributed Accelerated Systems,”
Innovative Computing Laboratory Technical Report, no. ICL-UT-19-05: University of Tennessee, April 2019.
|
|
Optimizing Batch HGEMM on Small Sizes Using Tensor Cores
, San Jose, CA, GPU Technology Conference (GTC), March 2019.
|
|
“Algorithms and Optimization Techniques for High-Performance Matrix-Matrix Multiplications of Very Small Matrices,”
Parallel Computing, vol. 81, pp. 1–21, January 2019.
|
|
FFT-ECP Fast Fourier Transform
, Houston, TX, 2019 ECP Annual Meeting (Research Poster), January 2019.
|
|
“Variable-Size Batched Gauss-Jordan Elimination for Block-Jacobi Preconditioning on Graphics Processors,”
Parallel Computing, vol. 81, pp. 131-146, January 2019.
|
|
“Analysis and Design Techniques towards High-Performance and Energy-Efficient Dense Linear Solvers on GPUs,”
IEEE Transactions on Parallel and Distributed Systems, vol. 29, issue 12, pp. 2700–2712, December 2018.
|
|
Accelerating 2D FFT: Exploit GPU Tensor Cores through Mixed-Precision
, Dallas, TX, The International Conference for High Performance Computing, Networking, Storage, and Analysis (SC18), ACM Student Research Poster, November 2018.
|
|
MATEDOR: MAtrix, TEnsor, and Deep-learning Optimized Routines
, Dallas, TX, The International Conference for High Performance Computing, Networking, Storage, and Analysis (SC18), Research Poster, November 2018.
|
|
“The Singular Value Decomposition: Anatomy of Optimizing an Algorithm for Extreme Scale,”
SIAM Review, vol. 60, issue 4, pp. 808–865, November 2018.
|
|
“Evaluation and Design of FFT for Distributed Accelerated Systems,”
ECP WBS 2.3.3.09 Milestone Report, no. FFT-ECP ST-MS-10-1216: Innovative Computing Laboratory, University of Tennessee, October 2018.
|
| “Task Based Cholesky Decomposition on Xeon Phi Architectures using OpenMP,” International Journal of Computational Science and Engineering (IJCSE), vol. 17, no. 3, October 2018. |
|
“Algorithms and Optimization Techniques for High-Performance Matrix-Matrix Multiplications of Very Small Matrices,”
Innovative Computing Laboratory Technical Report, no. ICL-UT-18-09: Innovative Computing Laboratory, University of Tennessee, September 2018.
|
|
“Optimizing GPU Kernels for Irregular Batch Workloads: A Case Study for Cholesky Factorization,”
IEEE High Performance Extreme Computing Conference (HPEC’18), Waltham, MA, IEEE, September 2018.
|
|
“Variable-Size Batched Condition Number Calculation on GPUs,”
SBAC-PAD, Lyon, France, September 2018.
|
|
Using GPU FP16 Tensor Cores Arithmetic to Accelerate Mixed-Precision Iterative Refinement Solvers and Reduce Energy Consumption
, Frankfurt, Germany, ISC High Performance (ISC18), Best Poster Award, June 2018.
|
|
“A Guide for Achieving High Performance with Very Small Matrices on GPUs: A Case Study of Batched LU and Cholesky Factorizations,”
IEEE Transactions on Parallel and Distributed Systems, vol. 29, issue 5, pp. 973–984, May 2018.
|
|
“Accelerating the SVD Bi-Diagonalization of a Batch of Small Matrices using GPUs,”
Journal of Computational Science, vol. 26, pp. 237–245, May 2018.
|
|
“Accelerating the SVD Two Stage Bidiagonal Reduction and Divide and Conquer Using GPUs,”
Parallel Computing, vol. 74, pp. 3–18, May 2018.
|
|
“Analyzing Performance of BiCGStab with Hierarchical Matrix on GPU Clusters,”
IEEE International Parallel and Distributed Processing Symposium (IPDPS), Vancouver, BC, Canada, IEEE, May 2018.
|
|
“Batched One-Sided Factorizations of Tiny Matrices Using GPUs: Challenges and Countermeasures,”
Journal of Computational Science, vol. 26, pp. 226–236, May 2018.
|
|
MAtrix, TEnsor, and Deep-learning Optimized Routines (MATEDOR)
, Washington, DC, NSF PI Meeting, Poster, April 2018.
|
|
Harnessing GPU's Tensor Cores Fast FP16 Arithmetic to Speedup Mixed-Precision Iterative Refinement Solvers and Achieve 74 Gflops/Watt on Nvidia V100
, San Jose, CA, GPU Technology Conference (GTC), Poster, March 2018.
|
|
“Optimization and Performance Evaluation of the IDR Iterative Krylov Solver on GPUs,”
The International Journal of High Performance Computing Applications, vol. 32, no. 2, pp. 220–230, March 2018.
|
|
Tensor Contractions using Optimized Batch GEMM Routines
, San Jose, CA, GPU Technology Conference (GTC), Poster, March 2018.
|
|
“A Jaccard Weights Kernel Leveraging Independent Thread Scheduling on GPUs,”
SBAC-PAD, Lyon, France, IEEE, 2018.
|
|
“POMPEI: Programming with OpenMP4 for Exascale Investigations,”
Innovative Computing Laboratory Technical Report, no. ICL-UT-17-09: University of Tennessee, December 2017.
|
|
“Sampling Algorithms to Update Truncated SVD,”
IEEE International Conference on Big Data, Boston, MA, IEEE, December 2017.
|
|
“Flexible Batched Sparse Matrix-Vector Product on GPUs,”
8th Workshop on Latest Advances in Scalable Algorithms for Large-Scale Systems (ScalA '17), Denver, CO, ACM Press, November 2017.
|
|
“Out of Memory SVD Solver for Big Data,”
2017 IEEE High Performance Extreme Computing Conference (HPEC'17), Waltham, MA, IEEE, September 2017.
|
|
“Power-aware Computing: Measurement, Control, and Performance Analysis for Intel Xeon Phi,”
2017 IEEE High Performance Extreme Computing Conference (HPEC'17), Best Paper Finalist, Waltham, MA, IEEE, September 2017.
|
|
“Towards Numerical Benchmark for Half-Precision Floating Point Arithmetic,”
2017 IEEE High Performance Extreme Computing Conference (HPEC), Waltham, MA, IEEE, September 2017.
|
|
“A Framework for Out of Memory SVD Algorithms,”
ISC High Performance 2017, pp. 158–178, June 2017.
|
|
“Factorization and Inversion of a Million Matrices using GPUs: Challenges and Countermeasures,”
Procedia Computer Science, vol. 108, pp. 606–615, June 2017.
|
|
“Novel HPC Techniques to Batch Execution of Many Variable Size BLAS Computations on GPUs,”
International Conference on Supercomputing (ICS '17), Chicago, Illinois, ACM, June 2017.
|
|
“Optimizing the SVD Bidiagonalization Process for a Batch of Small Matrices,”
International Conference on Computational Science (ICCS 2017), Zurich, Switzerland, Procedia Computer Science, June 2017.
|
|
“Fast Cholesky Factorization on GPUs for Batch and Native Modes in MAGMA,”
Journal of Computational Science, vol. 20, pp. 85–93, May 2017.
|
|
“Structure-aware Linear Solver for Realtime Convex Optimization for Embedded Systems,”
IEEE Embedded Systems Letters, vol. 9, issue 3, pp. 61–64, May 2017.
|
|
“With Extreme Computing, the Rules Have Changed,”
Computing in Science & Engineering, vol. 19, issue 3, pp. 52-62, May 2017.
|
|
“Small Tensor Operations on Advanced Architectures for High-Order Applications,”
University of Tennessee Computer Science Technical Report, no. UT-EECS-17-749: Innovative Computing Laboratory, University of Tennessee, April 2017.
|
|
“High-performance Cholesky Factorization for GPU-only Execution,”
Proceedings of the General Purpose GPUs (GPGPU-10), Austin, TX, ACM, February 2017.
|
|
“Investigating Half Precision Arithmetic to Accelerate Dense Linear System Solvers,”
ScalA17: 8th Workshop on Latest Advances in Scalable Algorithms for Large-Scale Systems, Denver, CO, ACM.
|
| “Non-GPU-resident Dense Symmetric Indefinite Factorization,” Concurrency and Computation: Practice and Experience, November 2016. |
|
“Towards Achieving Performance Portability Using Directives for Accelerators,”
The International Conference for High Performance Computing, Networking, Storage and Analysis (SC'16), Third Workshop on Accelerator Programming Using Directives (WACCPD), Salt Lake City, Utah, Innovative Computing Laboratory, University of Tennessee, November 2016.
|
| “Stability and Performance of Various Singular Value QR Implementations on Multicore CPU with a GPU,” ACM Transactions on Mathematical Software (TOMS), vol. 43, issue 2, October 2016. |
|
Accelerating Tensor Contractions for High-Order FEM on CPUs, GPUs, and KNLs
, Gatlinburg, TN, moky Mountains Computational Sciences and Engineering Conference (SMC16), Poster, September 2016.
|
|
“LU, QR, and Cholesky Factorizations: Programming Model, Performance Analysis and Optimization Techniques for the Intel Knights Landing Xeon Phi,”
IEEE High Performance Extreme Computing Conference (HPEC'16), Waltham, MA, IEEE, September 2016.
|
|
“Performance Analysis and Acceleration of Explicit Integration for Large Kinetic Networks using Batched GPU Computations,”
2016 IEEE High Performance Extreme Computing Conference (HPEC ‘16), Waltham, MA, IEEE, September 2016.
|
| “High-performance Matrix-matrix Multiplications of Very Small Matrices,” 22nd International European Conference on Parallel and Distributed Computing (Euro-Par'16), Grenoble, France, Springer International Publishing, August 2016. |
|
“MAGMA Batched: A Batched BLAS Approach for Small Matrix Factorizations and Applications on GPUs,”
Innovative Computing Laboratory Technical Report, no. ICL-UT-16-02: University of Tennessee, August 2016.
|
|
“High-Performance Tensor Contractions for GPUs,”
International Conference on Computational Science (ICCS'16), San Diego, CA, June 2016.
|
|
“Performance Tuning and Optimization Techniques of Fixed and Variable Size Batched Cholesky Factorization on GPUs,”
International Conference on Computational Science (ICCS'16), San Diego, CA, June 2016.
|
|
“Performance, Design, and Autotuning of Batched GEMM for GPUs,”
The International Supercomputing Conference (ISC High Performance 2016), Frankfurt, Germany, June 2016.
|
|
“Efficiency of General Krylov Methods on GPUs – An Experimental Study,”
The Sixth International Workshop on Accelerators and Hybrid Exascale Systems (AsHES), Chicago, IL, IEEE, May 2016.
|
|
“Hessenberg Reduction with Transient Error Resilience on GPU-Based Hybrid Architectures,”
30th IEEE International Parallel & Distributed Processing Symposium (IPDPS), Chicago, IL, IEEE, May 2016.
|
|
“Heterogeneous Streaming,”
The Sixth International Workshop on Accelerators and Hybrid Exascale Systems (AsHES), IPDPS 2016, Chicago, IL, IEEE, May 2016.
|
| “Linear Algebra Software for Large-Scale Accelerated Multicore Computing,” Acta Numerica, vol. 25, pp. 1-160, May 2016. |
|
“On the Development of Variable Size Batched Computation for Heterogeneous Parallel Architectures,”
The 17th IEEE International Workshop on Parallel and Distributed Scientific and Engineering Computing (PDSEC 2016), IPDPS 2016, Chicago, IL, IEEE, May 2016.
|
|
A Standard for Batched BLAS Routines
, Paris, France, 17th SIAM Conference on Parallel Processing for Scientific Computing (SIAM PP16), April 2016.
|
|
Cholesky Factorization on Batches of Matrices with Fixed and Variable Sizes
, San Jose, CA, GPU Technology Conference (GTC16), Poster, April 2016.
|
|
“Performance, Design, and Autotuning of Batched GEMM for GPUs,”
University of Tennessee Computer Science Technical Report, no. UT-EECS-16-739: University of Tennessee, February 2016.
|
|
“High-Performance Tensor Contractions for GPUs,”
University of Tennessee Computer Science Technical Report, no. UT-EECS-16-738: University of Tennessee, January 2016.
|
|
“Dense Symmetric Indefinite Factorization on GPU Accelerated Architectures,”
Lecture Notes in Computer Science, vol. 9573: Springer International Publishing, pp. 86-95, September 2015, 2016.
|
| “Adaptive Precision Solvers for Sparse Linear Systems,” 3rd International Workshop on Energy Efficient Supercomputing (E2SC '15), Austin, TX, ACM, November 2015. |
|
“Efficient Implementation Of Quantum Materials Simulations On Distributed CPU-GPU Systems,”
The International Conference for High Performance Computing, Networking, Storage and Analysis (SC15), Austin, TX, ACM, November 2015.
|
|
“GPU-accelerated Co-design of Induced Dimension Reduction: Algorithmic Fusion and Kernel Overlap,”
2nd International Workshop on Hardware-Software Co-Design for High Performance Computing, Austin, TX, ACM, November 2015.
|
|
“Mixed-precision Block Gram Schmidt Orthogonalization,”
6th Workshop on Latest Advances in Scalable Algorithms for Large-Scale Systems, Austin, TX, ACM, November 2015.
|
| “Performance of Random Sampling for Computing Low-rank Approximations of a Dense Matrix on GPUs,” The International Conference for High Performance Computing, Networking, Storage and Analysis (SC15), Austin, TX, ACM, November 2015. |
| “Randomized Algorithms to Update Partial Singular Value Decomposition on a Hybrid CPU/GPU Cluster,” The International Conference for High Performance Computing, Networking, Storage and Analysis (SC15), Austin, TX, ACM, November 2015. |
|
“Weighted Dynamic Scheduling with Many Parallelism Grains for Offloading of Numerical Workloads to Multiple Varied Accelerators,”
Proceedings of the 6th Workshop on Latest Advances in Scalable Algorithms for Large-Scale Systems (ScalA'15), vol. No. 5, Austin, TX, ACM, November 2015.
|
|
“Batched Matrix Computations on Hardware Accelerators Based on GPUs,”
2015 SIAM Conference on Applied Linear Algebra (SIAM LA), Atlanta, GA, SIAM, October 2015.
|
|
“Comparing Hybrid CPU-GPU and Native GPU-only Acceleration for Linear Algebra,”
2015 SIAM Conference on Applied Linear Algebra, Atlanta, GA, SIAM, October 2015.
|
|
“Efficient Eigensolver Algorithms on Accelerator Based Architectures,”
2015 SIAM Conference on Applied Linear Algebra (SIAM LA), Atlanta, GA, SIAM, October 2015.
|
|
“Mixed-precision orthogonalization process Performance on multicore CPUs with GPUs,”
2015 SIAM Conference on Applied Linear Algebra, Atlanta, GA, SIAM, October 2015.
|
|
“Parallel Programming Models for Dense Linear Algebra on Heterogeneous Systems,”
Supercomputing Frontiers and Innovations, vol. 2, no. 4, October 2015.
|
|
“Batched Matrix Computations on Hardware Accelerators,”
EuroMPI/Asia 2015 Workshop, Bordeaux, France, September 2015.
|
|
“MAGMA Embedded: Towards a Dense Linear Algebra Library for Energy Efficient Extreme Computing,”
2015 IEEE High Performance Extreme Computing Conference (HPEC ’15), (Best Paper Award), Waltham, MA, IEEE, September 2015.
|
|
Towards a High-Performance Tensor Algebra Package for Accelerators
, Gatlinburg, TN, moky Mountains Computational Sciences and Engineering Conference (SMC15), September 2015.
|
| “Cholesky Across Accelerators,” 17th IEEE International Conference on High Performance Computing and Communications (HPCC 2015), Elizabeth, NJ, IEEE, August 2015. |
|
“Flexible Linear Algebra Development and Scheduling with Cholesky Factorization,”
17th IEEE International Conference on High Performance Computing and Communications, Newark, NJ, August 2015.
|
| “Asynchronous Iterative Algorithm for Computing Incomplete Factorizations on GPUs,” International Supercomputing Conference (ISC 2015), Frankfurt, Germany, July 2015. |
|
“Framework for Batched and GPU-resident Factorization Algorithms to Block Householder Transformations,”
ISC High Performance, Frankfurt, Germany, Springer, July 2015.
|
|
“On the Design, Development, and Analysis of Optimized Matrix-Vector Multiplication Routines for Coprocessors,”
ISC High Performance 2015, Frankfurt, Germany, July 2015.
|
|
“Performance Analysis and Optimization of Two-Sided Factorization Algorithms for Heterogeneous Platform,”
International Conference on Computational Science (ICCS 2015), Reykjavík, Iceland, June 2015.
|
|
“Mixed-Precision Cholesky QR Factorization and its Case Studies on Multicore CPU with Multiple GPUs,”
SIAM Journal on Scientific Computing, vol. 37, no. 3, pp. C203-C330, May 2015.
|
|
“Accelerating the LOBPCG method on GPUs using a blocked Sparse Matrix Vector Product,”
Spring Simulation Multi-Conference 2015 (SpringSim'15), Alexandria, VA, SCS, April 2015.
|
|
“Performance Analysis and Design of a Hessenberg Reduction using Stabilized Blocked Elementary Transformations for New Architectures,”
The Spring Simulation Multi-Conference 2015 (SpringSim'15), Best Paper Award, Alexandria, VA, April 2015.
|
|
“Batched matrix computations on hardware accelerators based on GPUs,”
International Journal of High Performance Computing Applications, February 2015.
|
|
“Energy Efficiency and Performance Frontiers for Sparse Computations on GPU Supercomputers,”
Sixth International Workshop on Programming Models and Applications for Multicores and Manycores (PMAM '15), San Francisco, CA, ACM, February 2015.
|
|
“Optimization for Performance and Energy for Batched Matrix Computations on GPUs,”
8th Workshop on General Purpose Processing Using GPUs (GPGPU 8), San Francisco, CA, ACM, February 2015.
|
|
“Towards Batched Linear Solvers on Accelerated Hardware Platforms,”
8th Workshop on General Purpose Processing Using GPUs (GPGPU 8) co-located with PPOPP 2015, San Francisco, CA, ACM, February 2015.
|
|
“HPC Programming on Intel Many-Integrated-Core Hardware with MAGMA Port to Xeon Phi,”
Scientific Programming, vol. 23, issue 1, January 2015.
|
| “Acceleration of GPU-based Krylov solvers via Data Transfer Reduction,” International Journal of High Performance Computing Applications, 2015. |
|
“Computing Low-rank Approximation of a Dense Matrix on Multicore CPUs with a GPU and its Application to Solving a Hierarchically Semiseparable Linear System of Equations,”
Scientific Programming, 2015.
|
| “Domain Decomposition Preconditioners for Communication-Avoiding Krylov Methods on a Hybrid CPU/GPU Cluster,” The International Conference for High Performance Computing, Networking, Storage and Analysis (SC 14), New Orleans, LA, IEEE, November 2014. |
|
“Performance and Portability with OpenCL for Throughput-Oriented HPC Workloads Across Accelerators, Coprocessors, and Multicore Processors,”
5th Workshop on Latest Advances in Scalable Algorithms for Large-Scale Systems (ScalA '14), New Orleans, LA, IEEE, November 2014.
|
|
“Accelerating the LOBPCG method on GPUs using a blocked Sparse Matrix Vector Product,”
University of Tennessee Computer Science Technical Report, no. UT-EECS-14-731: University of Tennessee, October 2014.
|
|
“Unveiling the Performance-energy Trade-off in Iterative Linear System Solvers for Multithreaded Processors,”
Concurrency and Computation: Practice and Experience, vol. 27, issue 4, pp. 885-904, September 2014.
|
|
“LU Factorization of Small Matrices: Accelerating Batched DGETRF on the GPU,”
16th IEEE International Conference on High Performance Computing and Communications (HPCC), Paris, France, IEEE, August 2014.
|
|
“Heterogeneous Acceleration for Linear Algebra in Mulit-Coprocessor Environments,”
VECPAR 2014, Eugene, OR, June 2014.
|
|
“Mixed-precision orthogonalization scheme and adaptive step size for CA-GMRES on GPUs,”
VECPAR 2014 (Best Paper), Eugene, OR, June 2014.
|
|
“Self-Adaptive Multiprecision Preconditioners on Multicore and Manycore Architectures,”
VECPAR 2014, Eugene, OR, June 2014.
|
|
“A Novel Hybrid CPU-GPU Generalized Eigensolver for Electronic Structure Calculations Based on Fine Grained Memory Aware Tasks,”
International Journal of High Performance Computing Applications, vol. 28, issue 2, pp. 196-209, May 2014.
|
|
“A Step towards Energy Efficient Computing: Redesigning A Hydrodynamic Application on CPU-GPU,”
IPDPS 2014, Phoenix, AZ, IEEE, May 2014.
|
|
“clMAGMA: High Performance Dense Linear Algebra with OpenCL ,”
International Workshop on OpenCL, Bristol University, England, May 2014.
|
|
“Dynamically balanced synchronization-avoiding LU factorization with multicore and GPUs,”
Fourth International Workshop on Accelerators and Hybrid Exascale Systems (AsHES), IPDPS 2014, May 2014.
|
|
“Improving the performance of CA-GMRES on multicores with multiple GPUs,”
IPDPS 2014, Phoenix, AZ, IEEE, May 2014.
|
|
“Optimizing Krylov Subspace Solvers on Graphics Processing Units,”
Fourth International Workshop on Accelerators and Hybrid Exascale Systems (AsHES), IPDPS 2014, Phoenix, AZ, IEEE, May 2014.
|
|
“Unified Development for Mixed Multi-GPU and Multi-Coprocessor Environments using a Lightweight Runtime Environment,”
IPDPS 2014, Phoenix, AZ, IEEE, May 2014.
|
|
“Implementing a Sparse Matrix Vector Product for the SELL-C/SELL-C-σ formats on NVIDIA GPUs,”
University of Tennessee Computer Science Technical Report, no. UT-EECS-14-727: University of Tennessee, April 2014.
|
|
“Accelerating Numerical Dense Linear Algebra Calculations with GPUs,”
Numerical Computations with GPUs: Springer International Publishing, pp. 3-28, 2014.
|
|
“A Block-Asynchronous Relaxation Method for Graphics Processing Units,”
Journal of Parallel and Distributed Computing, vol. 73, issue 12, pp. 1613–1626, December 2013.
|
|
“Soft Error Resilient QR Factorization for Hybrid System with GPGPU,”
Journal of Computational Science, vol. 4, issue 6, pp. 457–464, November 2013.
|
|
“Tridiagonalization of a dense symmetric matrix on multiple GPUs and its application to symmetric eigenvalue problems,”
Concurrency and Computation: Practice and Experience, October 2013.
|
|
“Portable HPC Programming on Intel Many-Integrated-Core Hardware with MAGMA Port to Xeon Phi,”
PPAM 2013, Warsaw, Poland, September 2013.
|
|
“LU Factorization with Partial Pivoting for a Multicore System with Accelerators,”
IEEE Transactions on Parallel and Distributed Computing, vol. 24, issue 8, pp. 1613-1621, August 2013.
|
|
“Hydrodynamic Computation with Hybrid Programming on CPU-GPU Clusters,”
University of Tennessee Computer Science Technical Report, no. ut-cs-13-714, July 2013.
|
|
“Leading Edge Hybrid Multi-GPU Algorithms for Generalized Eigenproblems in Electronic Structure Calculations,”
International Supercomputing Conference (ISC), Lecture Notes in Computer Science, vol. 7905, Leipzig, Germany, Springer Berlin Heidelberg, pp. 67-80, June 2013.
|
|
“Transient Error Resilient Hessenberg Reduction on GPU-based Hybrid Architectures,”
UT-CS-13-712: University of Tennessee Computer Science Technical Report, June 2013.
|
|
“Hierarchical QR Factorization Algorithms for Multi-core Cluster Systems,”
Parallel Computing, vol. 39, issue 4-5, pp. 212-232, May 2013.
|
| “Tridiagonalization of a Symmetric Dense Matrix on a GPU Cluster,” The Third International Workshop on Accelerators and Hybrid Exascale Systems (AsHES), May 2013. |
|
“clMAGMA: High Performance Dense Linear Algebra with OpenCL,”
University of Tennessee Technical Report (Lawn 275), no. UT-CS-13-706: University of Tennessee, March 2013.
|
|
“Accelerating Linear System Solutions Using Randomization Techniques,”
ACM Transactions on Mathematical Software (also LAWN 246), vol. 39, issue 2, February 2013.
|
|
“Autotuning GEMM Kernels for the Fermi GPU,”
IEEE Transactions on Parallel and Distributed Systems, vol. 23, no. 11, November 2012.
|
|
“Providing GPU Capability to LU and QR within the ScaLAPACK Framework,”
University of Tennessee Computer Science Technical Report (also LAWN 272), no. UT-CS-12-699, September 2012.
|
|
“From CUDA to OpenCL: Towards a Performance-portable Solution for Multi-platform GPU Programming,”
Parallel Computing, vol. 38, no. 8, pp. 391-407, August 2012.
|
|
“GPU-Accelerated Asynchronous Error Correction for Mixed Precision Iterative Refinement,”
EuroPar 2012 (also LAWN 260), Rhodes Island, Greece, August 2012.
|
|
“Power Aware Computing on GPUs,”
SAAHPC '12 (Best Paper Award), Argonne, IL, July 2012.
|
| “A Class of Communication-Avoiding Algorithms for Solving General Dense Linear Systems on CPU/GPU Parallel Machines,” Proc. of the International Conference on Computational Science (ICCS), vol. 9, pp. 17-26, June 2012. |
|
“A Scalable Framework for Heterogeneous GPU-Based Clusters,”
The 24th ACM Symposium on Parallelism in Algorithms and Architectures (SPAA 2012), Pittsburgh, PA, USA, ACM, June 2012.
|
|
“Block-asynchronous Multigrid Smoothers for GPU-accelerated Systems,”
ICCS 2012, Omaha, NE, June 2012.
|
|
“Enabling and Scaling Matrix Computations on Heterogeneous Multi-Core and Multi-GPU Systems,”
26th ACM International Conference on Supercomputing (ICS 2012), San Servolo Island, Venice, Italy, ACM, June 2012.
|
| “One-Sided Dense Matrix Factorizations on a Multicore with Multiple GPU Accelerators,” The International Conference on Computational Science (ICCS), June 2012. |
|
“Hierarchical QR Factorization Algorithms for Multi-Core Cluster Systems,”
IPDPS 2012, the 26th IEEE International Parallel and Distributed Processing Symposium, Shanghai, China, IEEE Computer Society Press, May 2012.
|
| “Divide and Conquer on Hybrid GPU-Accelerated Multicore Systems,” SIAM Journal on Scientific Computing, vol. 34(2), pp. C70-C82, April 2012. |
|
“LU Factorization for Accelerator-Based Systems,”
IEEE/ACS AICCSA 2011, Sharm-El-Sheikh, Egypt, December 2011.
|
|
“Optimizing Symmetric Dense Matrix-Vector Multiplication on GPUs,”
ACM/IEEE Conference on Supercomputing (SC’11), Seattle, WA, November 2011.
|
|
“Hierarchical QR Factorization Algorithms for Multi-Core Cluster Systems,”
University of Tennessee Computer Science Technical Report (also Lawn 257), no. UT-CS-11-684, October 2011.
|
|
“Parallel Performance Measurement of Heterogeneous Parallel Systems with GPUs,”
International Conference on Parallel Processing (ICPP'11), Taipei, Taiwan, ACM, September 2011.
|
|
Power-aware Computing on GPGPUs
, Gatlinburg, TN, Fall Creek Falls Conference, Poster, September 2011.
|
|
“A Class of Hybrid LAPACK Algorithms for Multicore and GPU Architectures,”
Symposium for Application Accelerators in High Performance Computing (SAAHPC'11), Knoxville, TN, July 2011.
|
|
“Efficient Support for Matrix Computations on Heterogeneous Multi-core and Multi-GPU Architectures,”
University of Tennessee Computer Science Technical Report, UT-CS-11-668, (also Lawn 250), June 2011.
|
|
“Performance Portability of a GPU Enabled Factorization with the DAGuE Framework,”
IEEE Cluster: workshop on Parallel Programming on Accelerator Clusters (PPAC), June 2011.
|
|
“Autotuning GEMMs for Fermi,”
University of Tennessee Computer Science Technical Report, UT-CS-11-671, (also Lawn 245), April 2011.
|
| “A Hybridization Methodology for High-Performance Linear Algebra Software for GPUs,” in GPU Computing Gems, Jade Edition, vol. 2: Elsevier, pp. 473-484, 00 2011. |
|
“QUARK Users' Guide: QUeueing And Runtime for Kernels,”
University of Tennessee Innovative Computing Laboratory Technical Report, no. ICL-UT-11-02, 00 2011.
|
|
“Using MAGMA with PGI Fortran,”
PGI Insider, November 2010.
|
|
“QR Factorization on a Multicore Node Enhanced with Multiple GPU Accelerators,”
Proceedings of IPDPS 2011, no. ICL-UT-10-04, Anchorage, AK, October 2010.
|
|
“Mixed-Tool Performance Analysis on Hybrid Multicore Architectures,”
First International Workshop on Parallel Software Tools and Tool Infrastructures (PSTI 2010), San Diego, CA, September 2010.
|
|
“Tuning Principal Component Analysis for GRASS GIS on Multi-core and GPU Architectures,”
FOSS4G 2010, Barcelona, Spain, September 2010.
|
| “Divide & Conquer on Hybrid GPU-Accelerated Multicore Systems,” SIAM Journal on Scientific Computing (submitted), August 2010. |
|
“An Improved MAGMA GEMM for Fermi GPUs,”
University of Tennessee Computer Science Technical Report, no. UT-CS-10-655 (also LAPACK working note 227), July 2010.
|
|
“OpenCL Evaluation for Numerical Linear Algebra Library Development,”
Symposium on Application Accelerators in High-Performance Computing (SAAHPC '10), Knoxville, TN, July 2010.
|
|
Scheduling Cholesky Factorization on Multicore Architectures with GPU Accelerators
, Knoxville, TN, 2010 Symposium on Application Accelerators in High-Performance Computing (SAAHPC'10), Poster, July 2010.
|
|
“A Scalable High Performant Cholesky Factorization for Multicore with GPU Accelerators,”
Proc. of VECPAR'10 (to appear), Berkeley, CA, June 2010.
|
|
“Accelerating GPU Kernels for Dense Linear Algebra,”
Proc. of VECPAR'10, Berkeley, CA, June 2010.
|
|
“Hybrid Multicore Cholesky Factorization with Multiple GPU Accelerators,”
IEEE Transaction on Parallel and Distributed Systems (submitted), March 2010.
|
|
“Accelerating the Reduction to Upper Hessenberg, Tridiagonal, and Bidiagonal Forms through Hybrid GPU-Based Computing,”
Parallel Computing, vol. 36, no. 12, pp. 645-654, 00 2010.
|
| “An Improved MAGMA GEMM for Fermi GPUs,” International Journal of High Performance Computing, vol. 24, no. 4, pp. 511-515, 00 2010. |
|
“Faster, Cheaper, Better - A Hybridization Methodology to Develop Linear Algebra Software for GPUs,”
LAPACK Working Note, no. 230, 00 2010.
|
|
“Towards Dense Linear Algebra for Hybrid GPU Accelerated Manycore Systems,”
Parallel Computing, vol. 36, no. 5-6, pp. 232-240, 00 2010.
|
|
“Dense Linear Algebra Solvers for Multicore with GPU Accelerators,”
Parallel Distributed Processing, Workshops and Phd Forum (IPDPSW), 2010 IEEE International Symposium on, Atlanta, GA, pp. 1-8, 2010.
|
|
“Blas for GPUs,”
Scientific Computing with Multicore and Accelerators, Boca Raton, Florida, CRC Press, 2010.
|
| “Dense Linear Algebra for Hybrid GPU-based Systems,” Scientific Computing with Multicore and Accelerators, Boca Raton, Florida, CRC Press, 2010. |
|
“Accelerating Scientific Computations with Mixed Precision Algorithms,”
Computer Physics Communications, vol. 180, issue 12, pp. 2526-2533, December 2009.
|
|
Numerical Linear Algebra on Emerging Architectures: The PLASMA and MAGMA Projects
, Portland, OR, The International Conference for High Performance Computing, Networking, Storage, and Analysis (SC09), November 2009.
|
|
Numerical Linear Algebra on Hybrid Architectures: Recent Developments in the MAGMA Project
, Portland, Oregon, The International Conference for High Performance Computing, Networking, Storage, and Analysis (SC09), November 2009.
|
|
“A Note on Auto-tuning GEMM for GPUs,”
9th International Conference on Computational Science (ICCS 2009), no. 5544-5545, Baton Rouge, LA, pp. 884-892, May 2009.
|
|
“Accelerating the Reduction to Upper Hessenberg Form through Hybrid GPU-Based Computing,”
University of Tennessee Computer Science Technical Report, UT-CS-09-642 (also LAPACK Working Note 219), May 2009.
|
|
“Numerical Linear Algebra on Emerging Architectures: The PLASMA and MAGMA Projects,”
Journal of Physics: Conference Series, vol. 180, 00 2009.
|
|
Enhancing the Performance of Dense Linear Algebra Solvers on GPUs (in the MAGMA Project)
, Austin, TX, The International Conference for High Performance Computing, Networking, Storage, and Analysis (SC08), November 2008.
|
| “Some Issues in Dense Linear Algebra for Multicore and Special Purpose Architectures,” PARA 2008, 9th International Workshop on State-of-the-Art in Scientific and Parallel Computing, Trondheim Norway, May 2008. |
|
“Exploring New Architectures in Accelerating CFD for Air Force Applications,”
Proceedings of the DoD HPCMP User Group Conference, Seattle, Washington, January 2008.
|
|
“Some Issues in Dense Linear Algebra for Multicore and Special Purpose Architectures,”
University of Tennessee Computer Science Technical Report, UT-CS-08-615 (also LAPACK Working Note 200), January 2008.
|
|
“Towards Dense Linear Algebra for Hybrid GPU Accelerated Manycore Systems,”
University of Tennessee Computer Science Technical Report, UT-CS-08-632 (also LAPACK Working Note 210), January 2008.
|
|
Extending MAGMA Portability with OneAPI
, Dallas, TX, The International Conference for High Performance Computing, Networking, Storage, and Analysis (SC22), ACM Student Research Competition, November 2022.
|
|
Linear Algebra Prepara.on for Emergent Neural Network Architectures: MAGMA, BLAS, and Batched GPU Computing
, Virtual, LAPENNA Workshop, November 2021.
|
|
MAGMA: Evolution and Revolution
, Knoxville, TN, ICL Lunch Talk Seminar, July 2021.
|
|
Integrating Deep Learning in Domain Science at Exascale (MagmaDNN)
, virtual, DOD HPCMP seminar, December 2020.
|
|
How to Build Your Own Deep Neural Network
: PEARC20, July 2020.
|
|
MATEDOR: MAtrix, TEnsor, and Deep-learning Optimized Routines
, Seattle, WA, 2020 NSF Cyberinfrastructure for Sustained Scientific Innovation (CSSI) Principal Investigator Meeting, February 2020.
|
|
MATEDOR: MAtrix, TEnsor, and Deep-learning Optimized Routines
, Seattle, WA, 2020 NSF Cyberinfrastructure for Sustained Scientific Innovation (CSSI) Principal Investigator Meeting, February 2020.
|
|
“GPUDirect MPI Communications and Optimizations to Accelerate FFTs on Exascale Systems,”
EuroMPI'19 Posters, Zurich, Switzerland, no. icl-ut-19-06: ICL, September 2019.
|
|
Optimizing Batch HGEMM on Small Sizes Using Tensor Cores
, San Jose, CA, GPU Technology Conference (GTC), March 2019.
|
|
FFT-ECP Fast Fourier Transform
, Houston, TX, 2019 ECP Annual Meeting (Research Poster), January 2019.
|
|
MagmaDNN 0.2 High-Performance Data Analytics for Manycore GPUs and CPUs
: University of Tennessee, January 2019.
|
|
Accelerating 2D FFT: Exploit GPU Tensor Cores through Mixed-Precision
, Dallas, TX, The International Conference for High Performance Computing, Networking, Storage, and Analysis (SC18), ACM Student Research Poster, November 2018.
|
|
MATEDOR: MAtrix, TEnsor, and Deep-learning Optimized Routines
, Dallas, TX, The International Conference for High Performance Computing, Networking, Storage, and Analysis (SC18), Research Poster, November 2018.
|
|
Using GPU FP16 Tensor Cores Arithmetic to Accelerate Mixed-Precision Iterative Refinement Solvers and Reduce Energy Consumption
, Frankfurt, Germany, ISC High Performance (ISC18), Best Poster Award, June 2018.
|
|
MAtrix, TEnsor, and Deep-learning Optimized Routines (MATEDOR)
, Washington, DC, NSF PI Meeting, Poster, April 2018.
|
|
Harnessing GPU's Tensor Cores Fast FP16 Arithmetic to Speedup Mixed-Precision Iterative Refinement Solvers and Achieve 74 Gflops/Watt on Nvidia V100
, San Jose, CA, GPU Technology Conference (GTC), Poster, March 2018.
|
|
Tensor Contractions using Optimized Batch GEMM Routines
, San Jose, CA, GPU Technology Conference (GTC), Poster, March 2018.
|
|
Accelerating Linear Algebra with MAGMA
, Knoxville, TN, ECP Annual Meeting 2018, Tutorial, February 2018.
|
|
MagmaDNN â High-Performance Data Analytics for Manycore GPUs and CPUs
, Knoxville, TN, 2017 Summer Research Experiences for Undergraduate (REU), Presentation, December 2017.
|
|
Power-Aware HPC on Intel Xeon Phi KNL Processors
, Frankfurt, Germany, ISC High Performance (ISC17), Intel Booth Presentation, June 2017.
|
|
MAGMA Tensors and Batched Computing for Accelerating Applications on GPUs
, San Jose, CA, GPU Technology Conference (GTC17), Presentation in Session S7728, May 2017.
|
|
Accelerating Tensor Contractions in High-Order FEM with MAGMA Batched
, Atlanta, GA, SIAM Conference on Computer Science and Engineering (SIAM CSE17), Presentation, March 2017.
|
|
Accelerating Tensor Contractions for High-Order FEM on CPUs, GPUs, and KNLs
, Gatlinburg, TN, moky Mountains Computational Sciences and Engineering Conference (SMC16), Poster, September 2016.
|
|
A Standard for Batched BLAS Routines
, Paris, France, 17th SIAM Conference on Parallel Processing for Scientific Computing (SIAM PP16), April 2016.
|
|
Cholesky Factorization on Batches of Matrices with Fixed and Variable Sizes
, San Jose, CA, GPU Technology Conference (GTC16), Poster, April 2016.
|
|
On the Design, Autotuning, and Optimization of GPU Kernels for Kinetic Network Simulations Using Fast Explicit Integration and GPU Batched Computation
, Oak Ridge, TN, Joint Institute for Computational Sciences Seminar Series, Presentation, September 2015.
|
|
Towards a High-Performance Tensor Algebra Package for Accelerators
, Gatlinburg, TN, moky Mountains Computational Sciences and Engineering Conference (SMC15), September 2015.
|
|
Linear Algebra Software for High-Performance Computing (Part 2: Software for Hardware Accelerators and Coprocessors)
, Frankfurt, Germany, ISC High Performance (ISC18), Tutorial Presentation, June 2015.
|
|
MAGMA MIC: Optimizing Linear Algebra for Intel Xeon Phi
, Frankfurt, Germany, ISC High Performance (ISC15), Intel Booth Presentation, June 2015.
|
|
MAGMA MIC: Linear Algebra Library for Intel Xeon Phi Coprocessors
, Salt Lake City, UT, The International Conference for High Performance Computing, Networking, Storage, and Analysis (SC12), November 2012.
|
|
MAGMA: A New Generation of Linear Algebra Library for GPU and Multicore Architectures
, Salt Lake City, UT, The International Conference for High Performance Computing, Networking, Storage, and Analysis (SC12), Presentation, November 2012.
|
|
MAGMA: A Breakthrough in Solvers for Eigenvalue Problems
, San Jose, CA, GPU Technology Conference (GTC12), Presentation, May 2012.
|
|
MAGMA Tutorial
, Atlanta, GA, Keeneland Workshop, February 2012.
|
|
The Future of Computing: Software Libraries
, Savannah, GA, DOD CREATE Developers' Review, Keynote Presentation, February 2012.
|
|
Power-aware Computing on GPGPUs
, Gatlinburg, TN, Fall Creek Falls Conference, Poster, September 2011.
|
|
MAGMA - LAPACK for HPC on Heterogeneous Architectures
, Oak Ridge, TN, Titan Summit at Oak Ridge National Laboratory, Presentation, August 2011.
|
|
Matrix Algebra on GPU and Multicore Architectures
, Basel, Switzerland, Workshop on GPU-enabled Numerical Libraries, Presentation, May 2011.
|
|
MAGMA - LAPACK for GPUs
, Atlanta, GA, Keeneland GPU Tutorial, April 2011.
|
|
Accelerating Linear Algebra on Heterogeneous Architectures of Multicore and GPUs using MAGMA and DPLASMA and StarPU Schedulers
: 2010 Symposium on Application Accelerators in. High-Performance Computing (SAAHPC'10), Tutorial, July 2010.
|
|
Scheduling Cholesky Factorization on Multicore Architectures with GPU Accelerators
, Knoxville, TN, 2010 Symposium on Application Accelerators in High-Performance Computing (SAAHPC'10), Poster, July 2010.
|
| An Introduction to the MAGMA project - Acceleration of Dense Linear Algebra : NVIDIA Webinar, June 2010. |
|
Autotuning Dense Linear Algebra Libraries on GPUs
, Basel, Switzerland, Sixth International Workshop on Parallel Matrix Algorithms and Applications (PMAA 2010), June 2010.
|
|
Dense Linear Algebra Solvers for Multicore with GPU Accelerators
, Atlanta, GA, International Parallel and Distributed Processing Symposium (IPDPS 2010), April 2010.
|
|
Numerical Linear Algebra on Emerging Architectures: The PLASMA and MAGMA Projects
, Portland, OR, The International Conference for High Performance Computing, Networking, Storage, and Analysis (SC09), November 2009.
|
|
Numerical Linear Algebra on Hybrid Architectures: Recent Developments in the MAGMA Project
, Portland, Oregon, The International Conference for High Performance Computing, Networking, Storage, and Analysis (SC09), November 2009.
|
|
Enhancing the Performance of Dense Linear Algebra Solvers on GPUs (in the MAGMA Project)
, Austin, TX, The International Conference for High Performance Computing, Networking, Storage, and Analysis (SC08), November 2008.
|